





L'IA AlphaStar di DeepMind è il primo giocatore non umano di Starcraft II al livello Grandmaster

Per la prima volta un sistema di intelligenza artificiale è in grado di essere quasi sempre vincente al livello di difficoltà massimo del gioco
di Rosario Grasso pubblicata il 02 Novembre 2019, alle 14:31 nel canale VideogamesGoogleAlphabetBlizzard
Il livello Grandmaster di Starcraft II è riservato ai 200 migliori giocatori del server sulla base degli scontri 1v1. E l'intelligenza artificiale di DeepMind, una controllata del gruppo Alphabet, è riuscita a scalare le classifiche fino a conseguire il grado di Grandmaster. Questo vuol dire che l'intelligenza artificiale ha ottenuto risultati migliori rispetto al 99,8% dei giocatori umani.
Abbiamo già parlato di DeepMind AlphaStar a gennaio, quando ha sconfitto due tra i più quotati giocatori della scena competitiva di Starcraft II. Il risultato reclamato adesso da DeepMind è ancora più ragguardevole per la grande difficoltà a raggiungere il Grandmaster e perché il sistema è stato sottoposto a dei limiti in modo da non poter sfruttare dei vantaggi che un giocatore umano non potrebbe avere, per esempio in termini di intensità di azione e di porzione della mappa visibile.
L'intelligenza artificiale è riuscita in questo obiettivo tramite una tecnica di Apprendimento per Rinforzo (Reinforcement Learning) e un sistema multiagente.
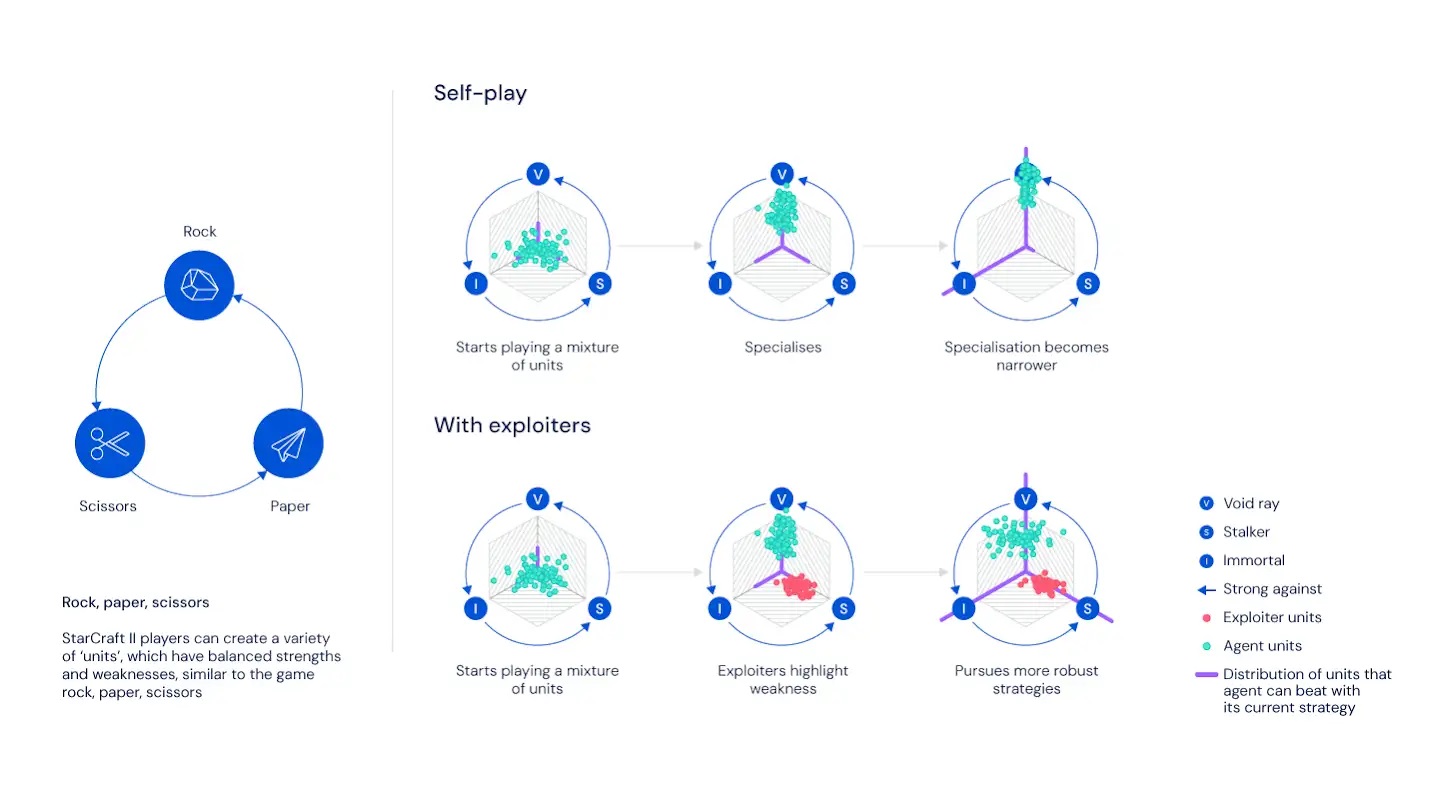
I giochi come Starcraft rappresentano un eccellente campo di prova per i sistemi di intelligenza artificiale come DeepMind, si legge nel documento. Uno gioco di strategia in tempo reale come questo mette i giocatori nelle condizioni di dover agire sulla base di informazioni limitate sulle quali prendere decisioni dinamiche, difficili e secondo tempistiche molto ristrette.
Durante le fasi di sperimentazione del sistema, DeepMind si è accorta che allenare l'intelligenza artificiale solamente contro sé stessa non era sufficiente per conseguire i miglioramenti necessari. "Un agente che gioca contro sé stesso può continuare a migliorare, ma può anche dimenticare come vincere contro una versione precedente di sé stesso". Dunque, si è cambiato sistema di apprendimento, sottoponendo match contro agenti con personalità di gioco differenti il cui scopo non fosse necessariamente vincere. Questi agenti hanno giocato solo per evidenziare i difetti della strategia dell'agente principale.
"Nel mondo reale può capitare di affrontare degli amici a scopo di allenamento, per confortarsi con strategie particolari non finalizzate a vincere. I compagni di allenamento non giocano per vincere contro ogni possibile avversario, ma si concentrano invece a sfruttare i difetti dell'amico che stanno allenando" si legge nel documento. "L'intuizione chiave è che giocare per vincere non è sufficiente: invece, abbiamo bisogno sia di agenti principali il cui obiettivo è vincere contro tutti, sia di agenti che si concentrano sull'aiutare l'agente principale a rafforzarsi esponendo i suoi difetti invece che cercare di vincere a ogni costo".


Un'altra sfida chiave è quella legata all'esplorazione. In ogni momento, un agente che gioca a Starcraft ha a disposizione 1026 possibili azioni e deve compiere migliaia di scelte prima di poter sapere se ha vinto o ha perso. La quantità di possibili scelte è dunque talmente ampia da rendere arduo trovare le strategie necessarie per vincere. "Anche con il sistema di auto-allenamento e una lega di agenti principali e agenti aiutanti non ci sarebbe alcuna possibilità per un sistema di intelligenza artificiale di sviluppare strategie di successo, senza una conoscenza preliminare" affermano i tecnici di DeepMind.
In una fase preliminare all'intelligenza artificiale vengono sottoposte una serie di partite di giocatori umani, dalla quale apprende delle possibili strategie che affina tramite il self-play, ovvero giocando contro sé stessa. "Per farlo abbiamo usato tecniche di apprendimento per imitazione combinate con architetture di reti neurali avanzate e tecniche di linguaggio di modellazione" (modelling language in inglese ndr). Questo sistema ha instaurato una strategia di base, che di per sé era in grado di sconfiggere l'84% dei giocatori umani. Inoltre, il sistema è in grado di prevedere azioni di apertura più o meno creative, in modo da bloccare in tempo le strategie di alto livello.
L'apprendimento per imitazione, unito alle tecniche di adattamento alle mutazioni attraverso la distribuzione di una "ricompensa" detta rinforzo che consiste nella valutazione della propria prestazione, consente ad AlphaStar di ottenere risultati molto brillanti, vincendo fondamentalmente tutte le partite che affronta.


AlphaStar ha giocato online in modo anonimo, utilizzando la piattaforma Battle.net e raggiungendo il livello di Grandmaster per tutte e tre le razze di Starcraft II, Terrestri, Zerg e Protoss. Come detto, non ha "barato" perché è stato sottoposto alle stesse limitazioni dei giocatori umani e a restrizioni alla velocità di azione. L'interfaccia e le restrizioni sono state approvate da un giocatore professionista.
In definitiva, secondo DeepMind, questi risultati forniscono una forte evidenza del fatto che le tecniche di apprendimento per scopi generici possono migliorare i sistemi di intelligenza artificiale fino a farli lavorare in ambienti complessi e dinamici che coinvolgono più attori. "Le tecniche che abbiamo usato per sviluppare AlphaStar aiuteranno a migliorare la sicurezza e la robustezza dei sistemi di intelligenza artificiale in generale e, speriamo, potrebbero servire a far progredire la nostra ricerca nel mondo reale".



 Recensione REDMAGIC Astra Gaming Tablet: che spettacolo di tablet!
Recensione REDMAGIC Astra Gaming Tablet: che spettacolo di tablet!  Dopo un mese, e 50 foto, cosa abbiamo capito della nuova Nintendo Switch 2
Dopo un mese, e 50 foto, cosa abbiamo capito della nuova Nintendo Switch 2 Gigabyte Aero X16 Copilot+ PC: tanta potenza non solo per l'IA
Gigabyte Aero X16 Copilot+ PC: tanta potenza non solo per l'IA Un'azienda cinese fondata solo un anno fa ha presentato un robot quadrupede che ha battuto Boston Dynamics
Un'azienda cinese fondata solo un anno fa ha presentato un robot quadrupede che ha battuto Boston Dynamics Norma, MSE e DepuChat: l'Italia tra i primi paesi a introdurre l'IA in Parlamento
Norma, MSE e DepuChat: l'Italia tra i primi paesi a introdurre l'IA in Parlamento I Feastables di MrBeast diventano lo snack ufficiale di Formula E
I Feastables di MrBeast diventano lo snack ufficiale di Formula E X, il fact-checking non funziona: oltre il 90% delle Community Notes non viene preso in considerazione
X, il fact-checking non funziona: oltre il 90% delle Community Notes non viene preso in considerazione La rivincita di Polestar, vendite in netta crescita nel Q2 e nel primo semestre: +38% e +51%
La rivincita di Polestar, vendite in netta crescita nel Q2 e nel primo semestre: +38% e +51%  15 milioni di euro per i computer quantistici fotonici europei, con QuiX Quantum
15 milioni di euro per i computer quantistici fotonici europei, con QuiX Quantum Tesla fa un mega sconto di 20.000 dollari in Canada nonostante i dazi, ma c'è il trucco
Tesla fa un mega sconto di 20.000 dollari in Canada nonostante i dazi, ma c'è il trucco Per il terzo anniversario del telescopio spaziale James Webb ecco la colorata immagine della Nebulosa Zampa di Gatto
Per il terzo anniversario del telescopio spaziale James Webb ecco la colorata immagine della Nebulosa Zampa di Gatto Perché continuo a ricevere telefonate dopo aver cambiato fornitore dell'energia elettrica e del gas?
Perché continuo a ricevere telefonate dopo aver cambiato fornitore dell'energia elettrica e del gas? Fujifilm annuncia le versioni infrarossi delle mirrorless GFX100 II e X-H2
Fujifilm annuncia le versioni infrarossi delle mirrorless GFX100 II e X-H2 Secondo i primi test, Grok 4 di Elon Musk ha già superato i rivali
Secondo i primi test, Grok 4 di Elon Musk ha già superato i rivali Vendeva segreti per la produzione di processori alla Russia: arrestato ingegnere nei Paesi Bassi
Vendeva segreti per la produzione di processori alla Russia: arrestato ingegnere nei Paesi Bassi Numeri choc: quest'anno sono cresciuti a ritmi esponenziali i contenuti di abuso su minori generati dallIA
Numeri choc: quest'anno sono cresciuti a ritmi esponenziali i contenuti di abuso su minori generati dallIA Addio Intel: RealSense vola da sola con 50 milioni per conquistare la robotica
Addio Intel: RealSense vola da sola con 50 milioni per conquistare la robotica



























0 Commenti
Gli autori dei commenti, e non la redazione, sono responsabili dei contenuti da loro inseriti - infoDevi effettuare il login per poter commentare
Se non sei ancora registrato, puoi farlo attraverso questo form.
Se sei già registrato e loggato nel sito, puoi inserire il tuo commento.
Si tenga presente quanto letto nel regolamento, nel rispetto del "quieto vivere".